




Notebooks

Categories



Cells
Premium

BioTuring
Classification of tumor and normal cells in the tumor microenvironment from scRNA-seq data is an ongoing challenge in human cancer study.
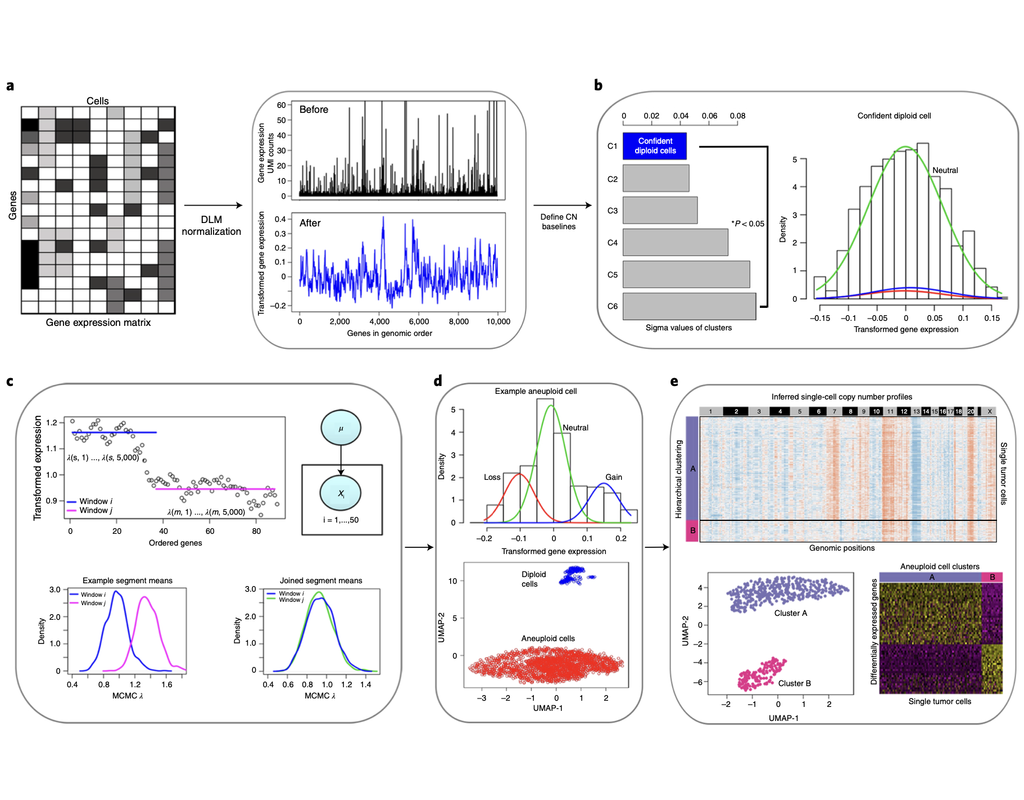
Copy number karyotyping of aneuploid tumors (***copyKAT***) (Gao, Ruli, et al., 2021) is a method proposed for identifying copy number variations in single-cell transcriptomics data. It is used to predict aneuploid tumor cells and delineate the clonal substructure of different subpopulations that coexist within the tumor mass.
In this notebook, we will illustrate a basic workflow of CopyKAT based on the tutorial provided on CopyKAT's repository. We will use a dataset of triple negative cancer tumors sequenced by 10X Chromium 3'-scRNAseq (GSM4476486) as an example. The dataset contains 20,990 features across 1,097 cells. We have modified the notebook to demonstrate how the tool works on BioTuring's platform.
BioTuring
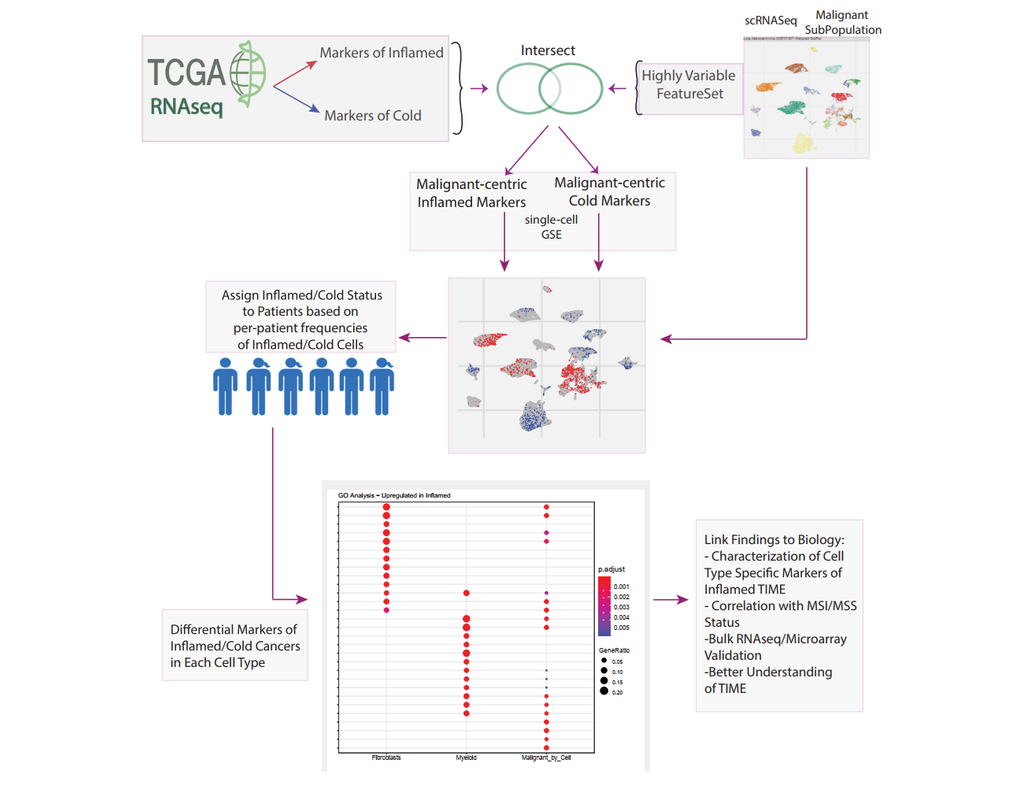
The development of immune checkpoint-based immunotherapies has been a major advancement in the treatment of cancer, with a subset of patients exhibiting durable clinical responses. A predictive biomarker for immunotherapy response is the pre-existing T-cell infiltration in the tumor immune microenvironment (TIME).
Bulk transcriptomics-based approaches can quantify the degree of T-cell infiltration using deconvolution methods and identify additional markers of inflamed/cold cancers at the bulk level. However, bulk techniques are unable to identify biomarkers of individual cell types. Although single-cell RNA sequencing (scRNAseq) assays are now being used to profile the TIME, to our knowledge there is no method of identifying patients with a T-cell inflamed TIME from scRNAseq data. Here, we describe a method, iBRIDGE, which integrates reference bulk RNAseq data with the malignant subset of scRNAseq datasets to identify patients with a T-cell inflamed TIME.
Utilizing two datasets with matched bulk data, we show iBRIDGE results correlated highly with bulk assessments (0.85 and 0.9 correlation coefficients). Using iBRIDGE, we identified markers of inflamed phenotypes in malignant cells, myeloid cells, and fibroblasts, establishing type I and type II interferon pathways as dominant signals, especially in malignant and myeloid cells, and finding the TGFβ-driven mesenchymal phenotype not only in fibroblasts but also in malignant cells.
Besides relative classification, per-patient average iBRIDGE scores and independent RNAScope quantifications were utilized for threshold-based absolute classification. Moreover, iBRIDGE can be applied to in vitro grown cancer cell lines and can identify the cell lines that are adapted from inflamed/cold patient tumors.
BioTuring
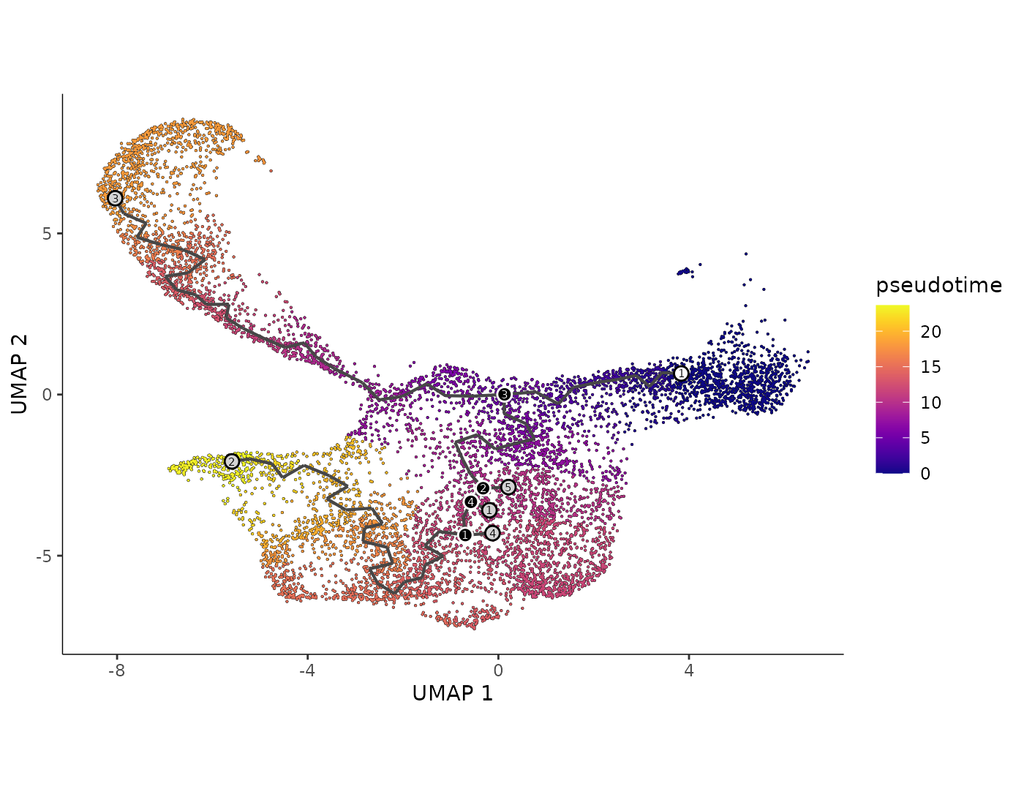
Build single-cell trajectories with the software that introduced **pseudotime**. Find out about cell fate decisions and the genes regulated as they're made.
Group and classify your cells based on gene expression. Identify new cell types and states and the genes that distinguish them.
Find genes that vary between cell types and states, over trajectories, or in response to perturbations using statistically robust, flexible differential analysis.
In development, disease, and throughout life, cells transition from one state to another. Monocle introduced the concept of **pseudotime**, which is a measure of how far a cell has moved through biological progress.
Many researchers are using single-cell RNA-Seq to discover new cell types. Monocle 3 can help you purify them or characterize them further by identifying key marker genes that you can use in follow-up experiments such as immunofluorescence or flow sorting.
**Single-cell trajectory analysis** shows how cells choose between one of several possible end states. The new reconstruction algorithms introduced in Monocle 3 can robustly reveal branching trajectories, along with the genes that cells use to navigate these decisions.
BioTuring
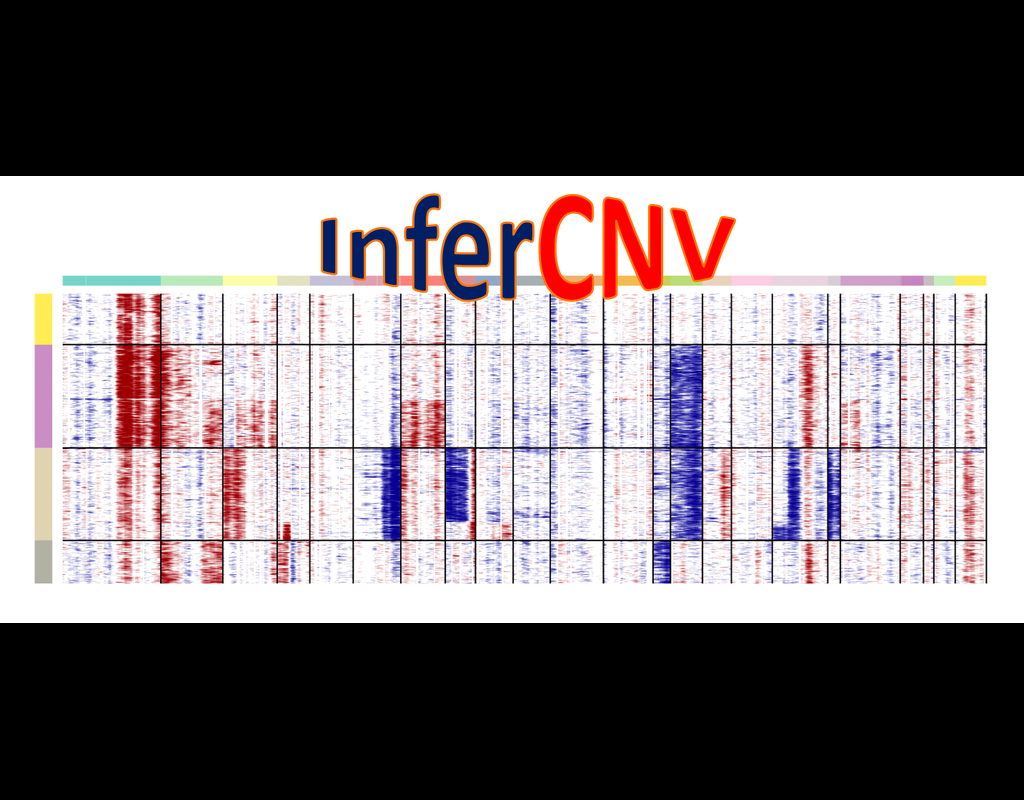
InferCNV is used to explore tumor single cell RNA-Seq data to identify evidence for somatic large-scale chromosomal copy number alterations, such as gains or deletions of entire chromosomes or large segments of chromosomes. This is done by exploring expression intensity of genes across positions of tumor genome in comparison to a set of reference 'normal' cells. A heatmap is generated illustrating the relative expression intensities across each chromosome, and it often becomes readily apparent as to which regions of the tumor genome are over-abundant or less-abundant as compared to that of normal cells.
**Infercnvpy** is a scalable python library to infer copy number variation (CNV) events from single cell transcriptomics data. It is heavliy inspired by InferCNV, but plays nicely with scanpy and is much more scalable.
Trends
BioTuring
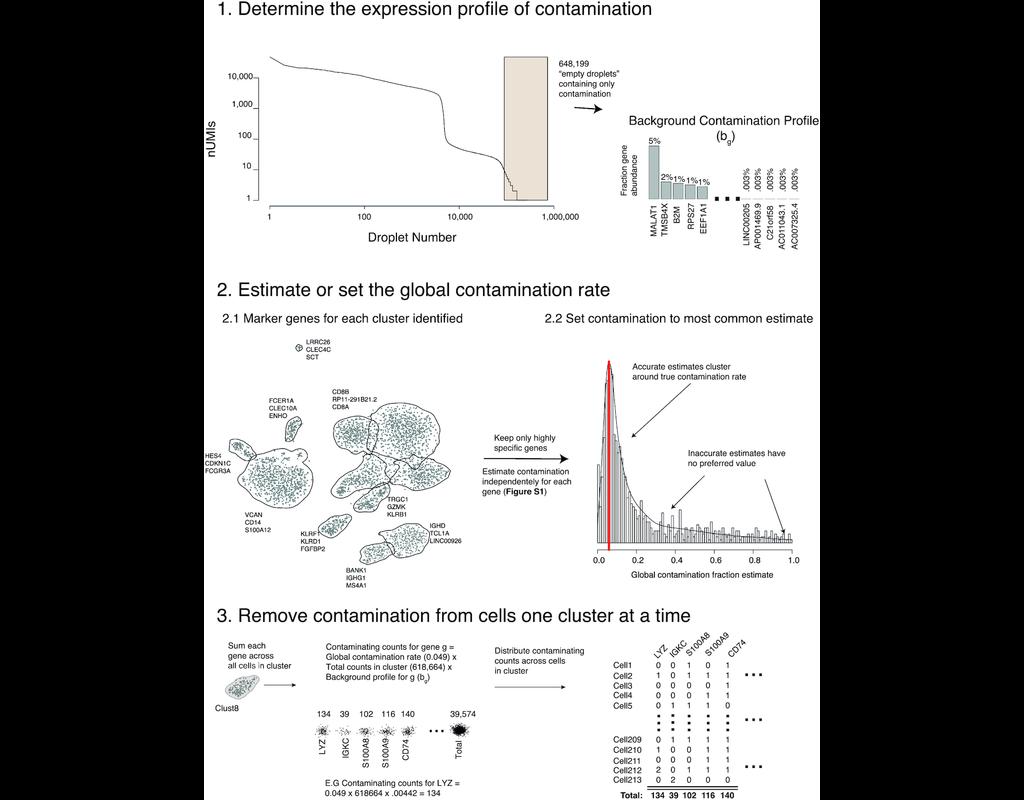
Droplet-based single-cell RNA sequence analyses assume that all acquired RNAs are endogenous to cells. However, there is a certain amount of cell-free mRNAs floating in the input solution (referred to as 'the soup'), created from cells in the input solution being lysed. These background mRNAs are then distributed into the droplets with cells and sequenced alongside them, resulting in background contamination that confounds the biological interpretation of single-cell transcriptomic data.
SoupX (Young and Behjati, 2020) is one of the methods proposed for ambient mRNA removal. In this notebook, we will illustrate a workflow example that applies SoupX to correct the ambient RNA in a dataset of 10k PBMC cells. The output of SoupX is a modified counts matrix, which can be used for any downstream analysis tool.