




Notebooks

Categories



Cells
Premium

BioTuring
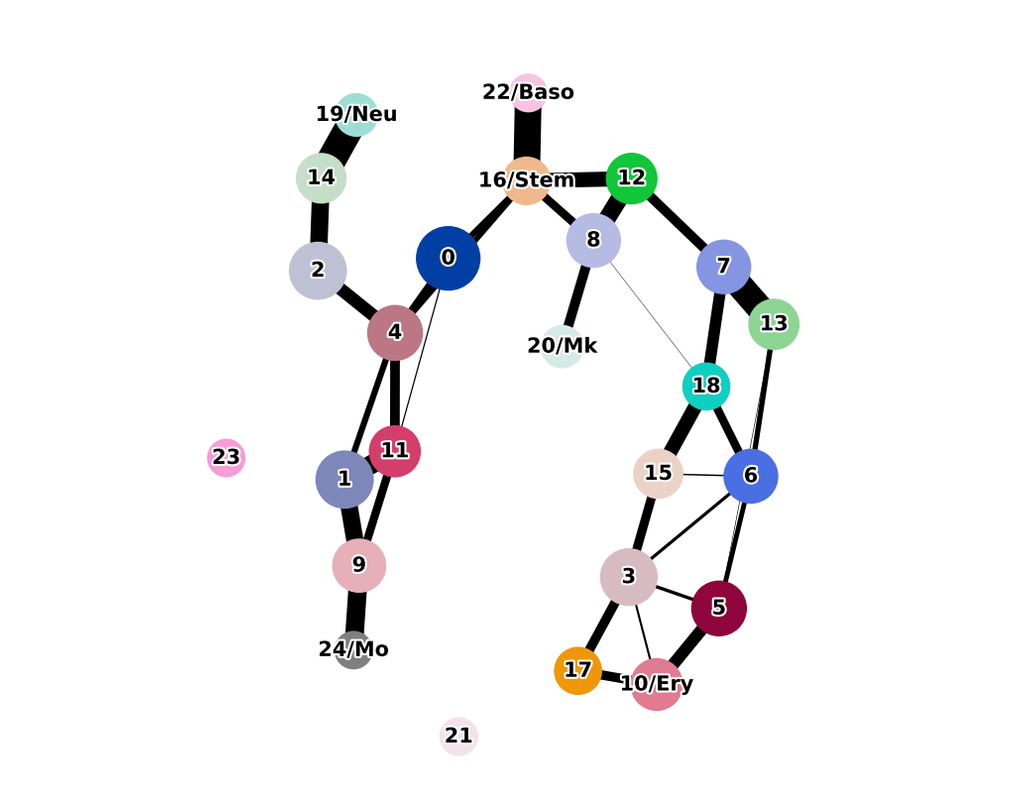
Mapping out the coarse-grained connectivity structures of complex manifolds
Biological systems often change over time, as old cells die and new cells are created through differentiation from progenitor cells. This means that at any given time, not all cells will be at the same stage of development. In this sense, a single-cell sample could contain cells at different stages of differentiation. By analyzing the data, we can identify which cells are at which stages and build a model for their biological transitions.
By quantifying the connectivity of partitions (groups, clusters) of the single-cell graph, partition-based graph abstraction (PAGA) generates a much simpler abstracted graph (PAGA graph) of partitions, in which edge weights represent confidence in the presence of connections.
In this notebook, we will introduce the concept of single-cell Trajectory Analysis using PAGA (Partition-based graph abstraction) in the context of hematopoietic differentiation.
BioTuring
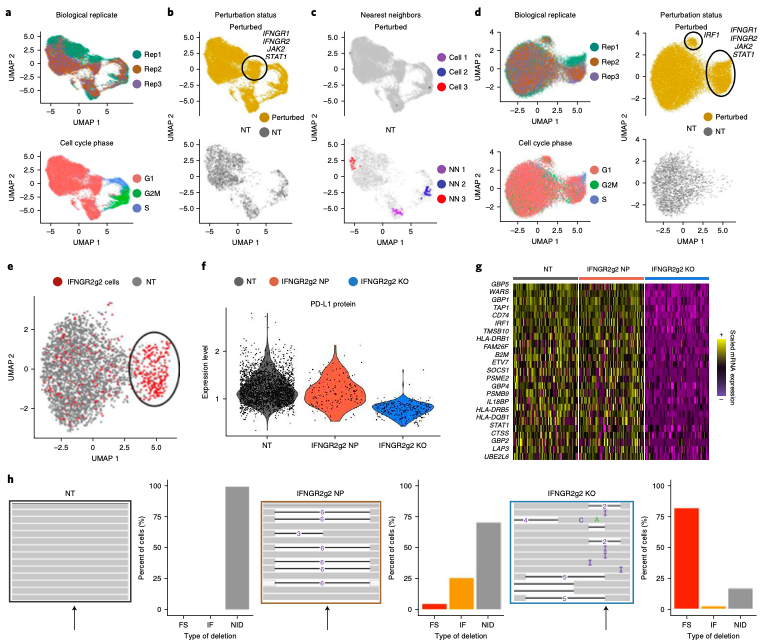
Expanded CRISPR-compatible CITE-seq (ECCITE-seq) which is built upon pooled CRISPR screens, allows to simultaneously measure transcriptomes, surface protein levels, and single-guide RNA (sgRNA) sequences at single-cell resolution. The technique enables multimodal characterization of each perturbation and effect exploration. However, it also encounters heterogeneity and complexity which can cause substantial noise into downstream analyses.
Mixscape (Papalexi, Efthymia, et al., 2021) is a computational framework proposed to substantially improve the signal-to-noise ratio in single-cell perturbation screens by identifying and removing confounding sources of variation.
In this notebooks, we demonstrate Mixscape's features using pertpy - a Python package offering a range of tools for perturbation analysis. The original pipeline of Mixscape implemented in R can be found here.

BioTuring
Doublets are a characteristic error source in droplet-based single-cell sequencing data where two cells are encapsulated in the same oil emulsion and are tagged with the same cell barcode. Across type doublets manifest as fictitious phenotypes that can be incorrectly interpreted as novel cell types. DoubletDetection present a novel, fast, unsupervised classifier to detect across-type doublets in single-cell RNA-sequencing data that operates on a count matrix and imposes no experimental constraints.
This classifier leverages the creation of in silico synthetic doublets to determine which cells in the
input count matrix have gene expression that is best explained by the combination of distinct cell
types in the matrix.
In this notebook, we will illustrate an example workflow for detecting doublets in single-cell RNA-seq count matrices.
BioTuring
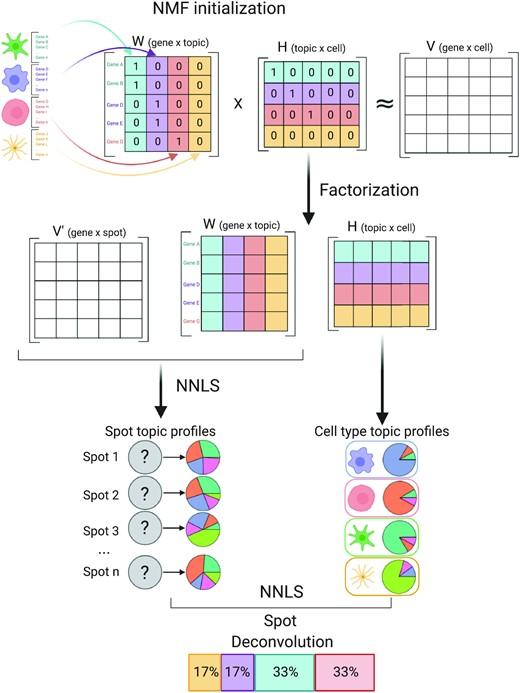
Spatially resolved gene expression profiles are key to understand tissue organization and function. However, spatial transcriptomics (ST) profiling techniques lack single-cell resolution and require a combination with single-cell RNA sequencing (scRNA-seq) information to deconvolute the spatially indexed datasets.
Leveraging the strengths of both data types, we developed SPOTlight, a computational tool that enables the integration of ST with scRNA-seq data to infer the location of cell types and states within a complex tissue. SPOTlight is centered around a seeded non-negative matrix factorization (NMF) regression, initialized using cell-type marker genes and non-negative least squares (NNLS) to subsequently deconvolute ST capture locations (spots).
Simulating varying reference quantities and qualities, we confirmed high prediction accuracy also with shallowly sequenced or small-sized scRNA-seq reference datasets. SPOTlight deconvolution of the mouse brain correctly mapped subtle neuronal cell states of the cortical layers and the defined architecture of the hippocampus. In human pancreatic cancer, we successfully segmented patient sections and further fine-mapped normal and neoplastic cell states.
Trained on an external single-cell pancreatic tumor references, we further charted the localization of clinical-relevant and tumor-specific immune cell states, an illustrative example of its flexible application spectrum and future potential in digital pathology.
Trends
BioTuring
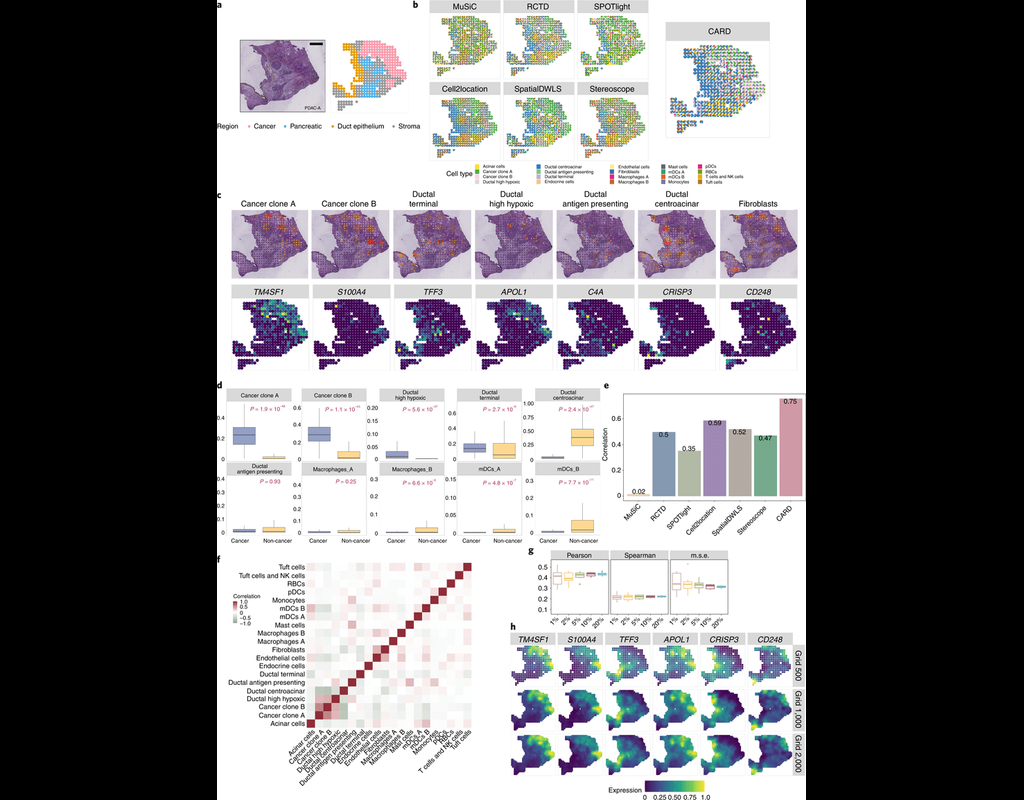
Many spatially resolved transcriptomic technologies do not have single-cell resolution but measure the average gene expression for each spot from a mixture of cells of potentially heterogeneous cell types.
Here, we introduce a deconvolution method, conditional autoregressive-based deconvolution (CARD), that combines cell-type-specific expression information from single-cell RNA sequencing (scRNA-seq) with correlation in cell-type composition across tissue locations. Modeling spatial correlation allows us to borrow the cell-type composition information across locations, improving accuracy of deconvolution even with a mismatched scRNA-seq reference.
**CARD** can also impute cell-type compositions and gene expression levels at unmeasured tissue locations to enable the construction of a refined spatial tissue map with a resolution arbitrarily higher than that measured in the original study and can perform deconvolution without an scRNA-seq reference.
Applications to four datasets, including a pancreatic cancer dataset, identified multiple cell types and molecular markers with distinct spatial localization that define the progression, heterogeneity and compartmentalization of pancreatic cancer.