




Notebooks

Categories



Cells
Premium


BioTuring
Single-cell RNA-seq datasets in diverse biological and clinical conditions provide great opportunities for the full transcriptional characterization of cell types.
However, the integration of these datasets is challeging as they remain biological and techinical differences. **Harmony** is an algorithm allowing fast, sensitive and accurate single-cell data integration.

BioTuring
Doublets are a characteristic error source in droplet-based single-cell sequencing data where two cells are encapsulated in the same oil emulsion and are tagged with the same cell barcode. Across type doublets manifest as fictitious phenotypes that can be incorrectly interpreted as novel cell types. DoubletDetection present a novel, fast, unsupervised classifier to detect across-type doublets in single-cell RNA-sequencing data that operates on a count matrix and imposes no experimental constraints.
This classifier leverages the creation of in silico synthetic doublets to determine which cells in the
input count matrix have gene expression that is best explained by the combination of distinct cell
types in the matrix.
In this notebook, we will illustrate an example workflow for detecting doublets in single-cell RNA-seq count matrices.
BioTuring
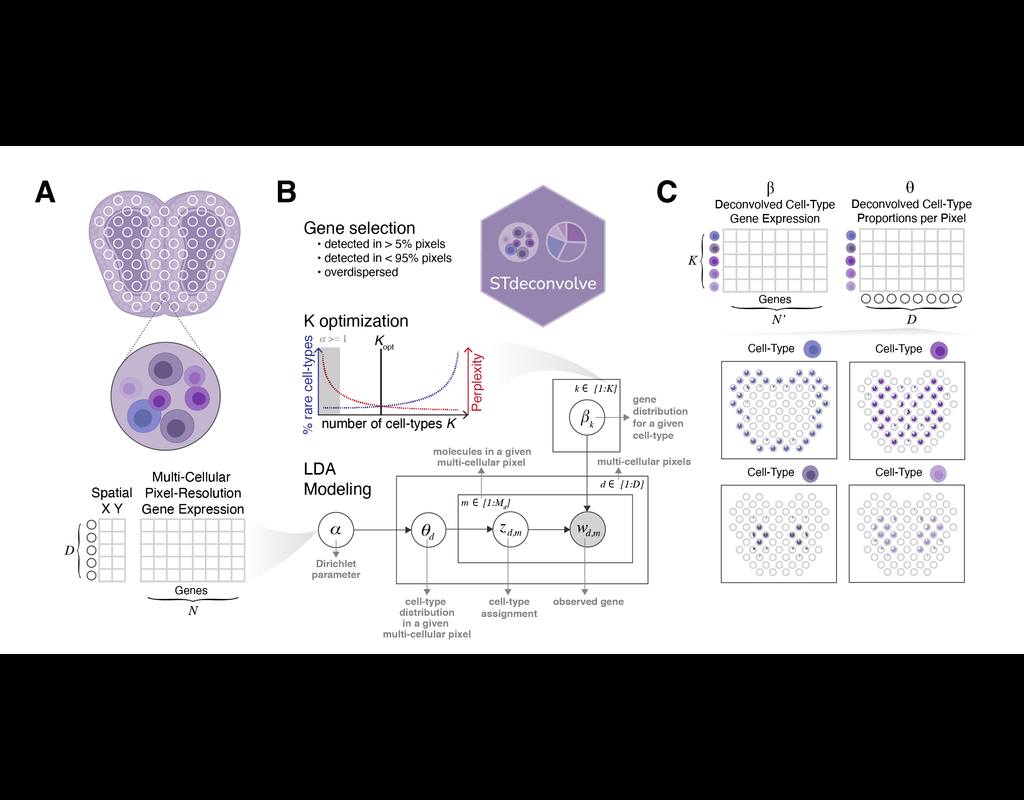
Recent technological advancements have enabled spatially resolved transcriptomic profiling but at multi-cellular pixel resolution, thereby hindering the identification of cell-type-specific spatial patterns and gene expression variation.
To address this challenge, we develop STdeconvolve as a reference-free approach to deconvolve underlying cell types comprising such multi-cellular pixel resolution spatial transcriptomics (ST) datasets. Using simulated as well as real ST datasets from diverse spatial transcriptomics technologies comprising a variety of spatial resolutions such as Spatial Transcriptomics, 10X Visium, DBiT-seq, and Slide-seq, we show that STdeconvolve can effectively recover cell-type transcriptional profiles and their proportional representation within pixels without reliance on external single-cell transcriptomics references.
**STdeconvolve** provides comparable performance to existing reference-based methods when suitable single-cell references are available, as well as potentially superior performance when suitable single-cell references are not available.
STdeconvolve is available as an open-source R software package with the source code available at https://github.com/JEFworks-Lab/STdeconvolve .
BioTuring
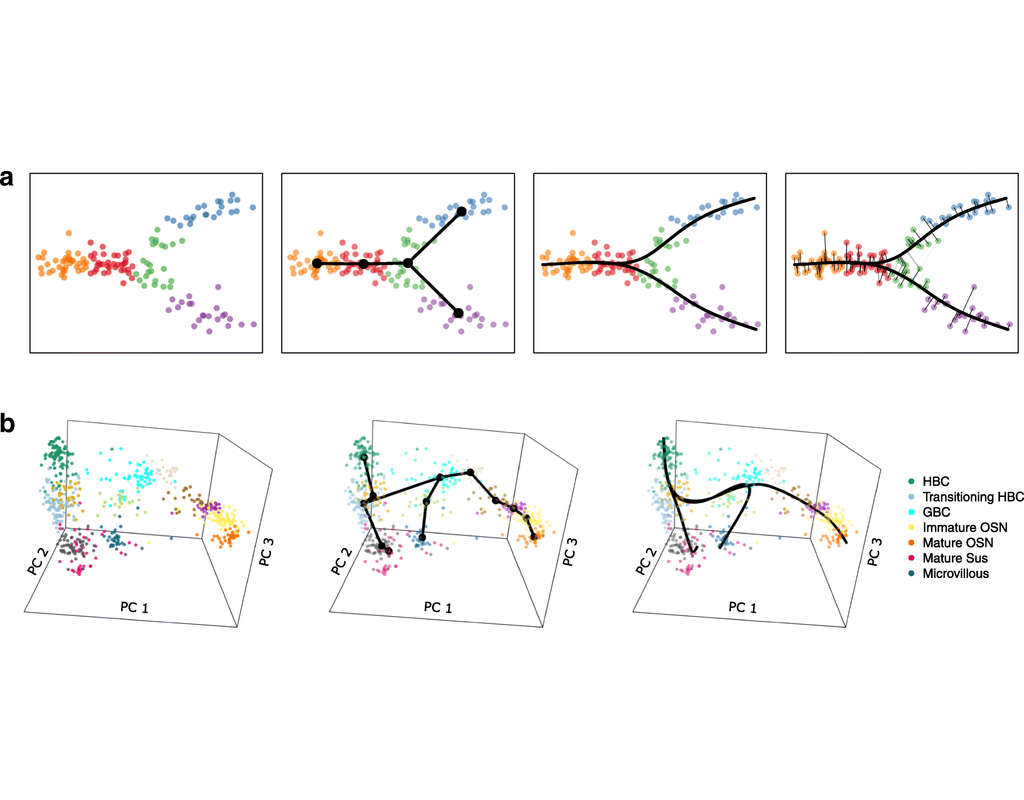
Single-cell RNA sequencing (scRNA-seq) data have allowed us to investigate cellular heterogeneity and the kinetics of a biological process. Some studies need to understand how cells change state, and corresponding genes during the process, but it is challenging to track the cell development in scRNA-seq protocols. Therefore, a variety of statistical and computational methods have been proposed for lineage inference (or pseudotemporal ordering) to reconstruct the states of cells according to the developmental process from the measured snapshot data. Specifically, lineage refers to an ordered transition of cellular states, where individual cells represent points along. pseudotime is a one-dimensional variable representing each cell’s transcriptional progression toward the terminal state.
Slingshot which is one of the methods suggested for lineage reconstruction and pseudotime inference from single-cell gene expression data. In this notebook, we will illustrate an example workflow for cell lineage and pseudotime inference using Slingshot. The notebook is inspired by Slingshot's vignette and modified to demonstrate how the tool works on BioTuring's platform.
Trends
BioTuring
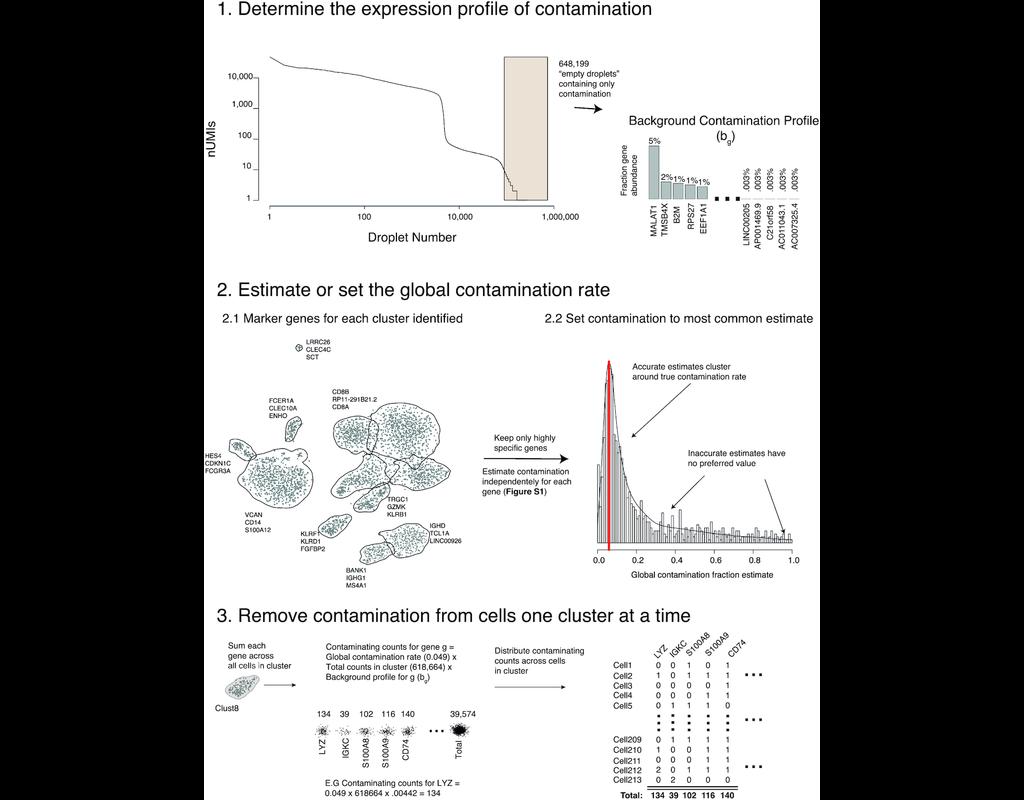
Droplet-based single-cell RNA sequence analyses assume that all acquired RNAs are endogenous to cells. However, there is a certain amount of cell-free mRNAs floating in the input solution (referred to as 'the soup'), created from cells in the input solution being lysed. These background mRNAs are then distributed into the droplets with cells and sequenced alongside them, resulting in background contamination that confounds the biological interpretation of single-cell transcriptomic data.
SoupX (Young and Behjati, 2020) is one of the methods proposed for ambient mRNA removal. In this notebook, we will illustrate a workflow example that applies SoupX to correct the ambient RNA in a dataset of 10k PBMC cells. The output of SoupX is a modified counts matrix, which can be used for any downstream analysis tool.