




Notebooks

Categories



Cells
Premium

BioTuring
Spatially resolved gene expression profiles are key to understand tissue organization and function. However, spatial transcriptomics (ST) profiling techniques lack single-cell resolution and require a combination with single-cell RNA sequencing (scRNA-seq) information to deconvolute the spatially indexed datasets.
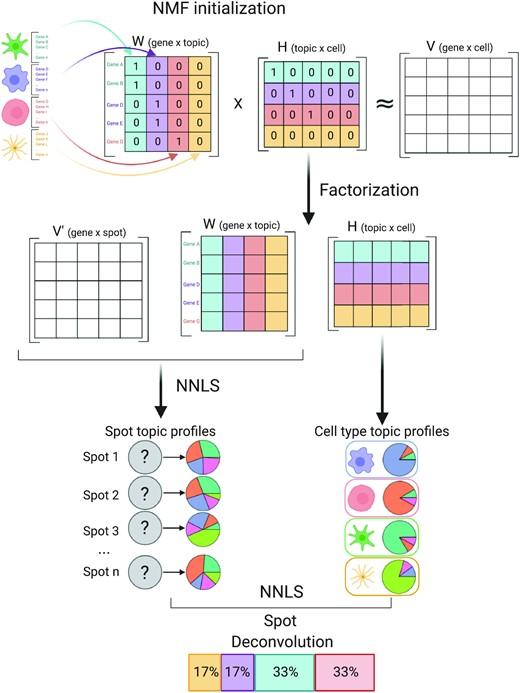
Leveraging the strengths of both data types, we developed SPOTlight, a computational tool that enables the integration of ST with scRNA-seq data to infer the location of cell types and states within a complex tissue. SPOTlight is centered around a seeded non-negative matrix factorization (NMF) regression, initialized using cell-type marker genes and non-negative least squares (NNLS) to subsequently deconvolute ST capture locations (spots).
Simulating varying reference quantities and qualities, we confirmed high prediction accuracy also with shallowly sequenced or small-sized scRNA-seq reference datasets. SPOTlight deconvolution of the mouse brain correctly mapped subtle neuronal cell states of the cortical layers and the defined architecture of the hippocampus. In human pancreatic cancer, we successfully segmented patient sections and further fine-mapped normal and neoplastic cell states.
Trained on an external single-cell pancreatic tumor references, we further charted the localization of clinical-relevant and tumor-specific immune cell states, an illustrative example of its flexible application spectrum and future potential in digital pathology.

BioTuring
The recent development of experimental methods for measuring chromatin state at single-cell resolution has created a need for computational tools capable of analyzing these datasets. Here we developed Signac, a framework for the analysis of single-cell chromatin data, as an extension of the Seurat R toolkit for single-cell multimodal analysis.
**Signac** enables an end-to-end analysis of single-cell chromatin data, including peak calling, quantification, quality control, dimension reduction, clustering, integration with single-cell gene expression datasets, DNA motif analysis, and interactive visualization.
Furthermore, Signac facilitates the analysis of multimodal single-cell chromatin data, including datasets that co-assay DNA accessibility with gene expression, protein abundance, and mitochondrial genotype. We demonstrate scaling of the Signac framework to datasets containing over 700,000 cells.
BioTuring
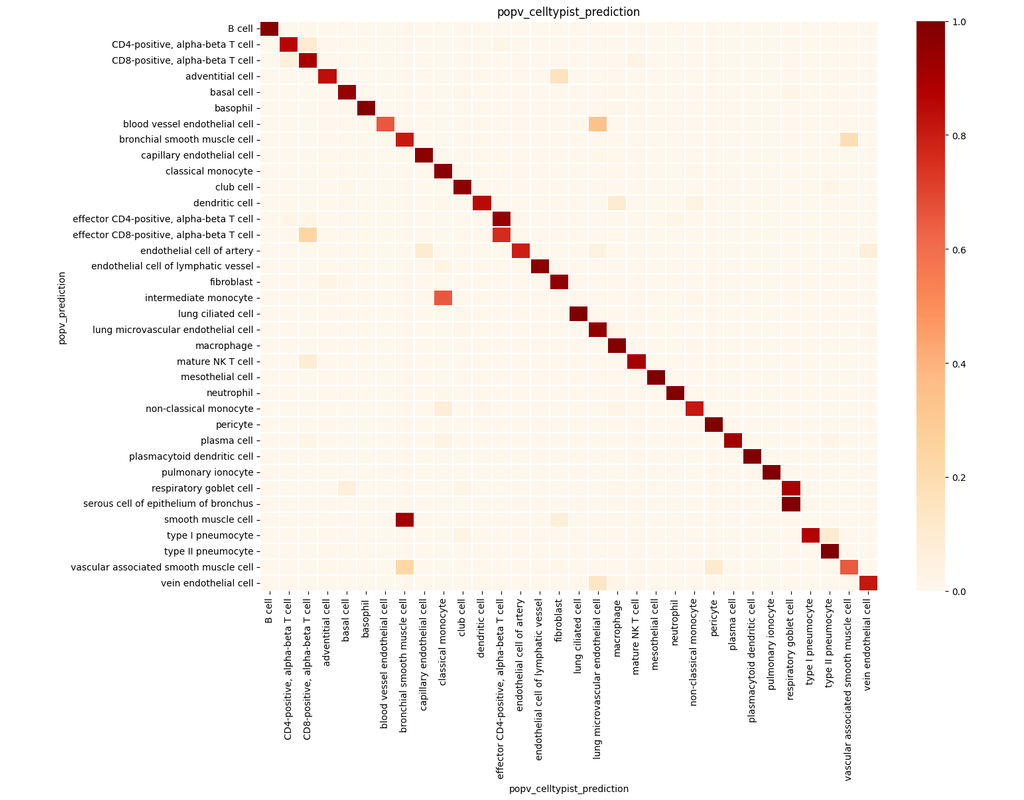
PopV uses popular vote of a variety of cell-type transfer tools to classify cell-types in a query dataset based on a test dataset.
Using this variety of algorithms, they compute the agreement between those algorithms and use this agreement to predict which cell-types have a high likelihood of the same cell-types observed in the reference.

BioTuring
The development of large-scale single-cell atlases has allowed describing cell states in a more detailed manner. Meanwhile, current deep leanring methods enable rapid analysis of newly generated query datasets by mapping them into reference atlases.
expiMap (‘explainable programmable mapper’) Lotfollahi, Mohammad, et al. is one of the methods proposed for single-cell reference mapping. Furthermore, it incorporates prior knowledge from gene sets databases or users to analyze query data in the context of known gene programs (GPs).
Trends
BioTuring
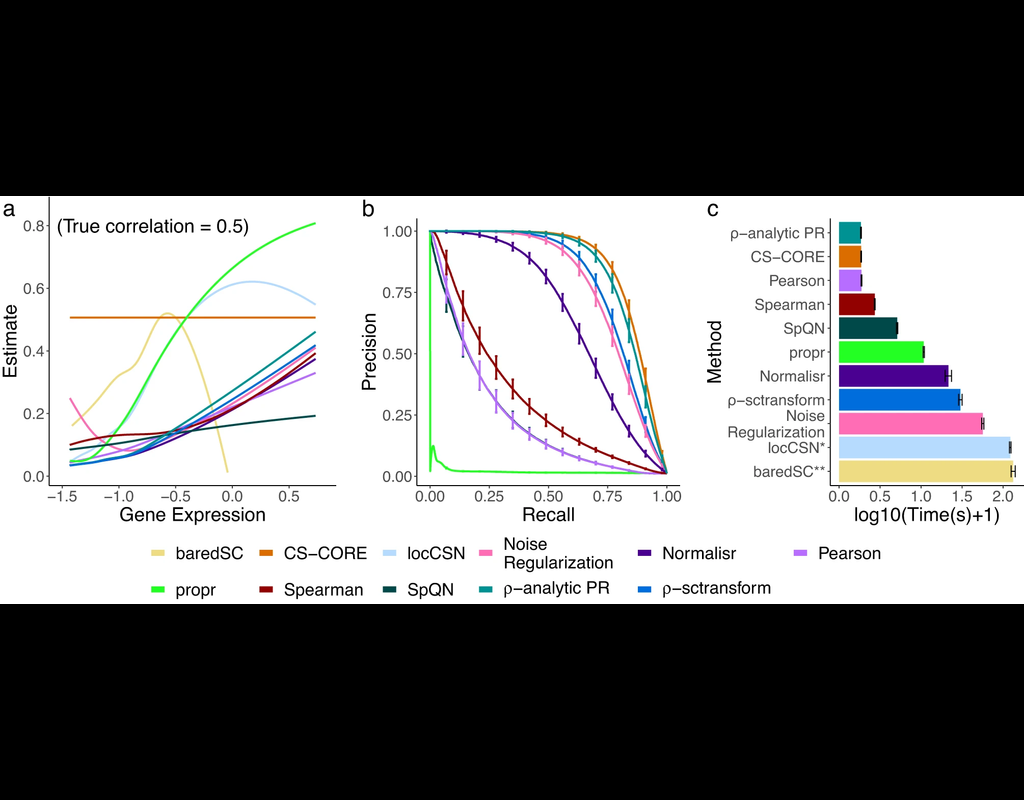
The recent development of single-cell RNA-sequencing (scRNA-seq) technology has enabled us to infer cell-type-specific co-expression networks, enhancing our understanding of cell-type-specific biological functions. However, existing methods proposed for this task still face challenges due to unique characteristics in scRNA-seq data, such as high sequencing depth variations across cells and measurement errors.
CS-CORE (Su, C., Xu, Z., Shan, X. et al., 2023), an R package for cell-type-specific co-expression inference, explicitly models sequencing depth variations and measurement errors in scRNA-seq data.
In this notebook, we will illustrate an example workflow of CS-CORE using a dataset of Peripheral Blood Mononuclear Cells (PBMC) from COVID patients and healthy controls (Wilk et al., 2020). The notebook content is inspired by CS-CORE's vignette and modified to demonstrate how the tool works on BioTuring's platform.