




Notebooks

Categories



Cells
Premium

BioTuring
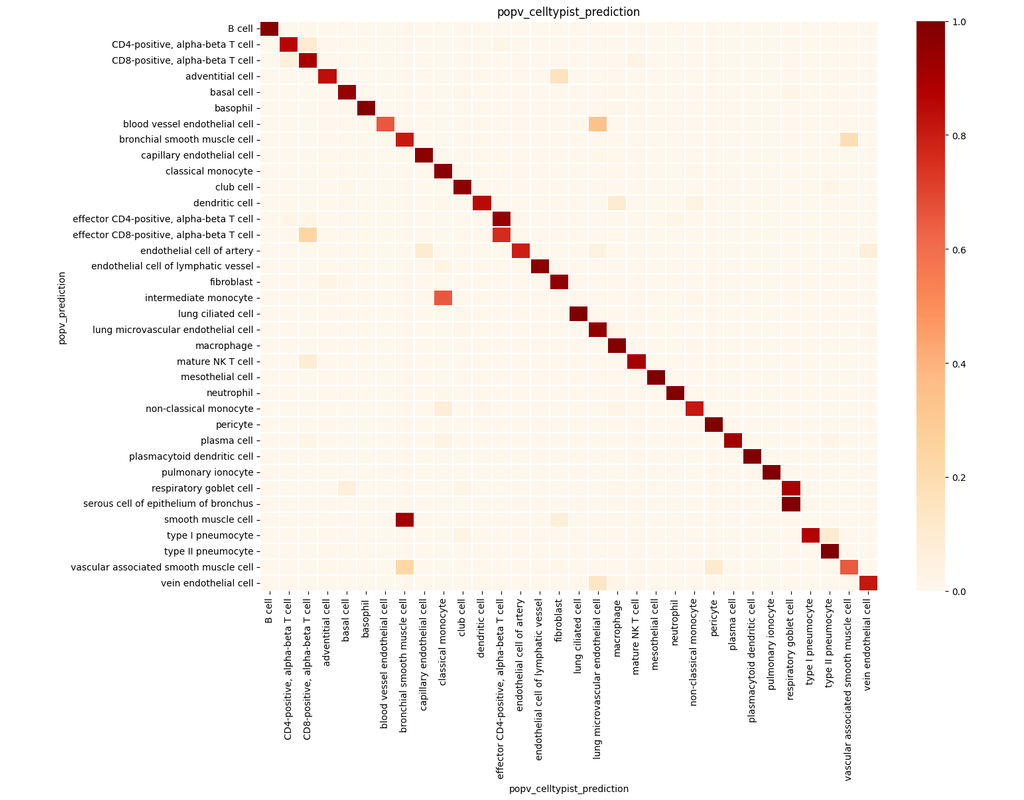
PopV uses popular vote of a variety of cell-type transfer tools to classify cell-types in a query dataset based on a test dataset.
Using this variety of algorithms, they compute the agreement between those algorithms and use this agreement to predict which cell-types have a high likelihood of the same cell-types observed in the reference.
BioTuring
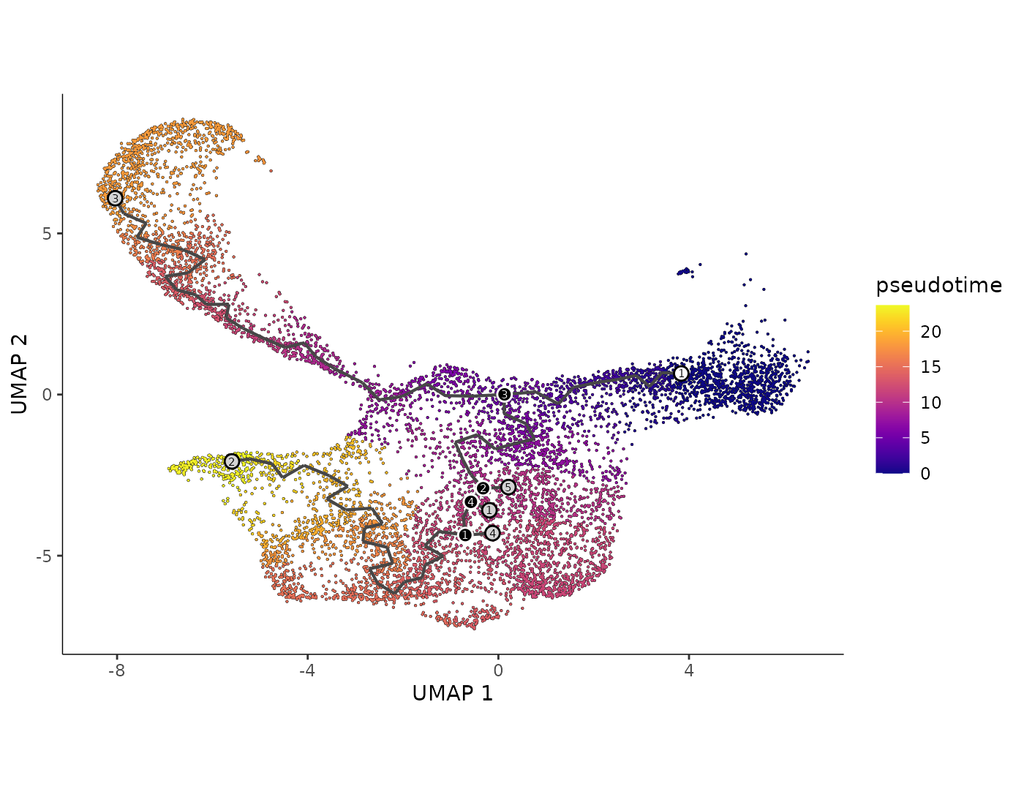
Build single-cell trajectories with the software that introduced **pseudotime**. Find out about cell fate decisions and the genes regulated as they're made.
Group and classify your cells based on gene expression. Identify new cell types and states and the genes that distinguish them.
Find genes that vary between cell types and states, over trajectories, or in response to perturbations using statistically robust, flexible differential analysis.
In development, disease, and throughout life, cells transition from one state to another. Monocle introduced the concept of **pseudotime**, which is a measure of how far a cell has moved through biological progress.
Many researchers are using single-cell RNA-Seq to discover new cell types. Monocle 3 can help you purify them or characterize them further by identifying key marker genes that you can use in follow-up experiments such as immunofluorescence or flow sorting.
**Single-cell trajectory analysis** shows how cells choose between one of several possible end states. The new reconstruction algorithms introduced in Monocle 3 can robustly reveal branching trajectories, along with the genes that cells use to navigate these decisions.
BioTuring
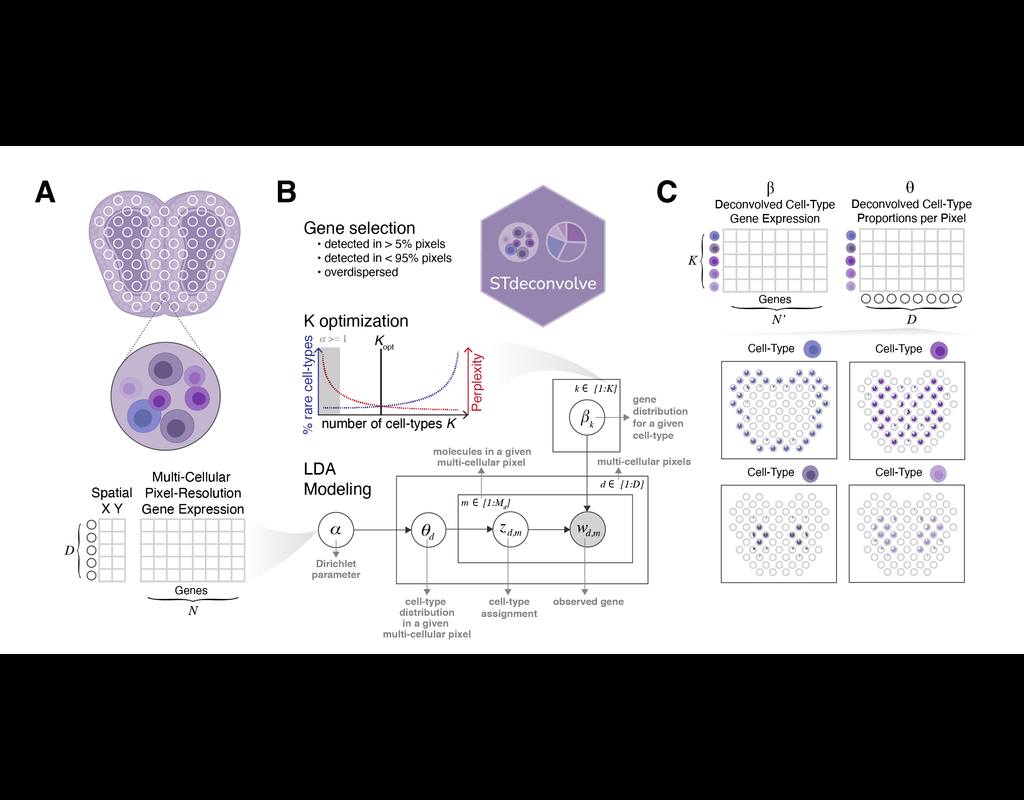
Recent technological advancements have enabled spatially resolved transcriptomic profiling but at multi-cellular pixel resolution, thereby hindering the identification of cell-type-specific spatial patterns and gene expression variation.
To address this challenge, we develop STdeconvolve as a reference-free approach to deconvolve underlying cell types comprising such multi-cellular pixel resolution spatial transcriptomics (ST) datasets. Using simulated as well as real ST datasets from diverse spatial transcriptomics technologies comprising a variety of spatial resolutions such as Spatial Transcriptomics, 10X Visium, DBiT-seq, and Slide-seq, we show that STdeconvolve can effectively recover cell-type transcriptional profiles and their proportional representation within pixels without reliance on external single-cell transcriptomics references.
**STdeconvolve** provides comparable performance to existing reference-based methods when suitable single-cell references are available, as well as potentially superior performance when suitable single-cell references are not available.
STdeconvolve is available as an open-source R software package with the source code available at https://github.com/JEFworks-Lab/STdeconvolve .

BioTuring
Doublets are a characteristic error source in droplet-based single-cell sequencing data where two cells are encapsulated in the same oil emulsion and are tagged with the same cell barcode. Across type doublets manifest as fictitious phenotypes that can be incorrectly interpreted as novel cell types. DoubletDetection present a novel, fast, unsupervised classifier to detect across-type doublets in single-cell RNA-sequencing data that operates on a count matrix and imposes no experimental constraints.
This classifier leverages the creation of in silico synthetic doublets to determine which cells in the
input count matrix have gene expression that is best explained by the combination of distinct cell
types in the matrix.
In this notebook, we will illustrate an example workflow for detecting doublets in single-cell RNA-seq count matrices.
Trends
BioTuring
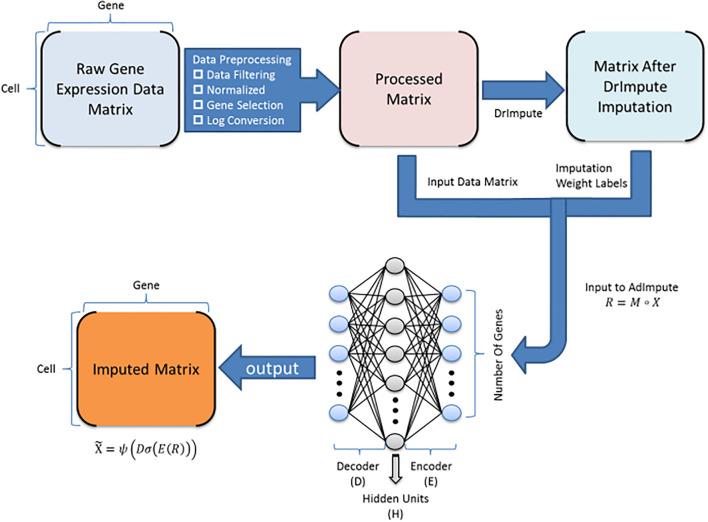
Single-cell RNA sequencing (scRNA-seq) protocols often face challenges in measuring the expression of all genes within a cell due to various factors, such as technical noise, the sensitivity of scRNA-seq techniques, or sample quality. This limitation gives rise to a need for the prediction of unmeasured gene expression values (also known as dropout imputation) from scRNA-seq data.
ADImpute (Leote A, 2023) is an R package combining several dropout imputation methods, including two existing methods (DrImpute, SAVER), two novel implementations: Network, a gene regulatory network-based approach using gene-gene relationships learned from external data, and Baseline, a method corresponding to a sample-wide average..
This notebook is to illustrate an example workflow of ADImpute on sample datasets loaded from the package. The notebook content is inspired from ADImpute's vignette and modified to demonstrate how the tool works on BioTuring's platform.
| Notebooks |
|---|